Operating Systems for Intelligent Networked System
(Press ? for help, n and p for next and previous slide; usage hints)
Introduction
Core Questions
- What is OS and Kernel?
- What is virtual memory?
- How can RAM be (de-) allocated flexibly for multitasking?
- How does the OS manage the shared resource CPU? What goals are pursued?
- What exactly are threads?
- How does the OS schedule threads for execution?
- What can go wrong with concurrent computations?
- What is a race condition?
- What is the difference between bare metal, embedded OS and full-fledged OS?
Learning Objectives
- Explain notion of Operating System and its goals
- Explain notion of kernel with system call API
- Explain different between various OS / bare metal options
- Explain mechanisms and uses for virtual memory
- Explain notions of process, thread, multitasking
- Explain race condition, mutual exclusion
Table of Contents
What is an OS?
“Hello World!” on Bare Metal
void main() { // set up serial console uart_init(); // say hello uart_puts("Hello World!\n"); // echo everything back while(1) { uart_send(uart_getc()); } }
Source code from Github
UART Initialization
void uart_init() { register unsigned int r; /* initialize UART */ *AUX_ENABLE |=1; // enable UART1, AUX mini uart *AUX_MU_CNTL = 0; *AUX_MU_LCR = 3; // 8 bits *AUX_MU_MCR = 0; *AUX_MU_IER = 0; *AUX_MU_IIR = 0xc6; // disable interrupts *AUX_MU_BAUD = 270; // 115200 baud /* map UART1 to GPIO pins */ r=*GPFSEL1; r&=~((7<<12)|(7<<15)); // gpio14, gpio15 r|=(2<<12)|(2<<15); // alt5 *GPFSEL1 = r; *GPPUD = 0; // enable pins 14 and 15 r=150; while(r--) { asm volatile("nop"); } *GPPUDCLK0 = (1<<14)|(1<<15); r=150; while(r--) { asm volatile("nop"); } *GPPUDCLK0 = 0; // flush GPIO setup *AUX_MU_CNTL = 3; // enable Tx, Rx }
UART Send Char and String
void uart_send(unsigned int c) { /* wait until we can send */ do{asm volatile("nop");}while(!(*AUX_MU_LSR&0x20)); /* write the character to the buffer */ *AUX_MU_IO=c; }
void uart_puts(char *s) { while(*s) { /* convert newline to carrige return + newline */ if(*s=='\n') uart_send('\r'); uart_send(*s++); } }
UART Get Char
char uart_getc() { char r; /* wait until something is in the buffer */ do{asm volatile("nop");}while(!(*AUX_MU_LSR&0x01)); /* read it and return */ r=(char)(*AUX_MU_IO); /* convert carrige return to newline */ return r=='\r'?'\n':r; }
Problem for Bare Metal Approach
- What if we also need to read a sensor and send its measurement out?
- Possible solution: interrupt, event-based, etc.
- What if we need to allocate memory dynamically?
- E.g., storing all sensor readings for future inspection
- Possible solution: malloc/free (fragmentation), memory pool, etc.
- Need to manage device drivers
- E.g., UART, network interfaces, sensors, actuators, etc.
Popular operating System for IoT
Popular operating System for Endpoints
Popular operating System for Gateways/Edge
Definition of Operating System
- Definition from [Hai19]: Software
- that uses hardware resources of a computer system
- to provide support for the execution of other software.
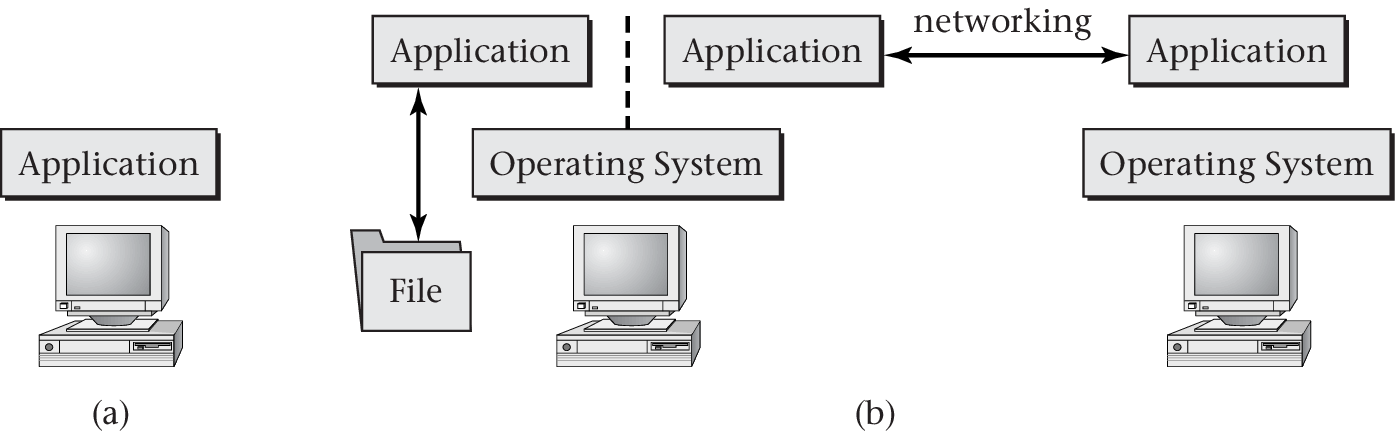
“Figure 1.1 of [Hai17]” by Max Hailperin under CC BY-SA 3.0; converted from GitHub
OS Services
- A full-fledged OS services/features/functionality includes
- Dynamically allocate/free memory
- Support for multiple concurrent computations
- Run programs, divide hardware, manage state
- Control interactions between concurrent computations
- E.g., locking, private memory
- Also, networking, file system, device drivers(even GUI) support
“Figure 1.1 of [Hai17]” by Max Hailperin under CC BY-SA 3.0; converted from GitHub
Kernel
- Boundary between OS and applications is fuzzy
- Kernel is fundamental, core part of OS
OS Architecture and Kernel Variants
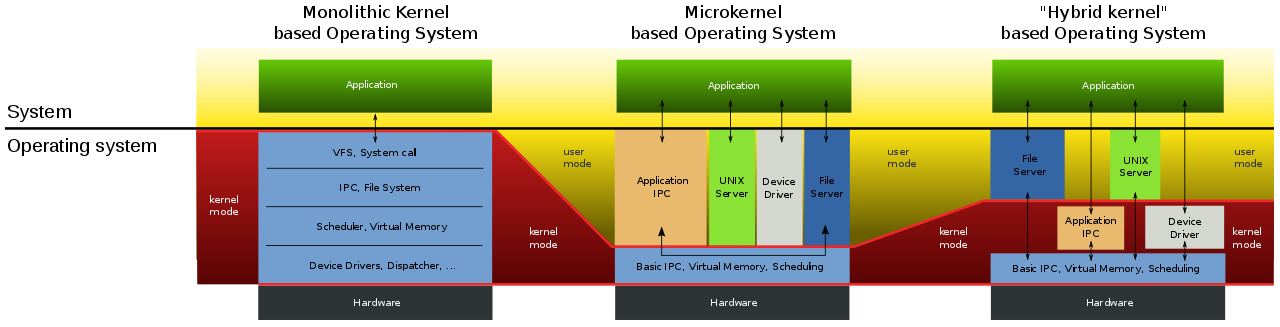
See this map of the Linux kernel for a real-life monolithic example
OS Kernel
- OS runs as code on CPU
- Just as any other program
- Kernel contains central part of OS
- Provides API for OS services via system calls (next slide)
- Code and data of kernel typically main memory resident
- Kernel functionality runs in kernel mode of CPU, reacts to system calls and interrupts
- Variants (previous slide)
- Monolithic (“large,” all OS related services)
- Micro kernel (“small,” only necessary services)
- “Best” design depends on application
- Provable security only with micro kernels (seL4)
Interacting with Kernel: System Calls
- System call = function = part of kernel API
- Implementation of OS service
- E.g., process execution, main memory allocation, hardware resource access (e.g., keyboard, network, disk, graphics card)
- Implementation of OS service
- Different OSs may offer different system calls (i.e., offer incompatible APIs)
- With different implementations
- With different calling conventions
- The Portable Operating System Interface (*POSIX is a family of standards specified by the IEEE Computer Society for maintaining compatibility between operating systems.
- Many OS are POSIX-complaint: Linux, Android
Memory Management
Virtual Memory

Physical vs virtual addresses
- Physical: Addresses used on memory bus
- RAM is byte-addressed (1 byte = 8 bits)
- Each
addressselects a byte (not a word as in Hack) - (Machine instructions typically operate on words (= multiple bytes), though)
- Virtual: Addresses used by processes(running programs)
Virtual Addresses
- Additional layer of abstraction provided by OS
- Programmers do not need to worry about physical memory locations at all
- Pieces of data (and instructions) are identified by virtual addresses
- At different points in time, the same piece of data (identified by its virtual address) may reside at different locations in RAM (identified by different physical addresses) or may not be present in RAM at all
- OS keeps track of (virtual) address spaces:
What (virtual address) is located where (physical address)
- Supported by hardware, memory management unit (MMU)
- Translation of virtual into physical addresses (see next slide)
- Supported by hardware, memory management unit (MMU)
Processes
- OS manages running programs via processes (Other names: tasks, … )
- Process ≈ a running program occupying a virtual address space
Web browser may open multiple processes
- Each process has its own virtual address space
- Starting at virtual address 0, mapped per process to RAM by the OS, e.g.:
- Virtual address 0 of process P1 located at physical address 0
- Virtual address 0 of process P2 located at physical address 16384
- Virtual address 0 of process P3 not located in RAM at all
- Processes may share data (with OS permission), e.g.:
BoundedBufferlocated at RAM address 42- Identified by virtual address 42 in P1, by 4138 in P3
- Starting at virtual address 0, mapped per process to RAM by the OS, e.g.:
- Address space of process is shared by its threads
- E.g., for all threads of P2, virtual address 0 is associated with physical address 16384
Memory Layout for a C program
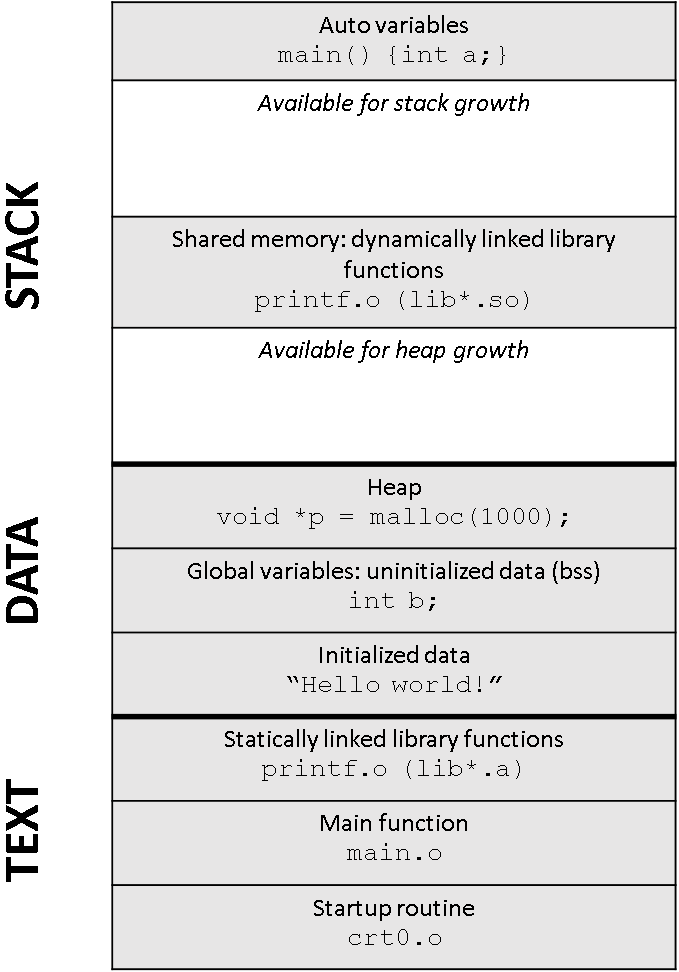
Memory Layout for a C program
#include <stdio.h> #include <malloc.h> const char *hello = "Hello world!\n"; int b; int main() { int a = 1; b = 2; void *p = malloc(1000); printf(hello); return 0; }
Uses for Virtual Memory
Private Storage
- Each process has its own address space, isolated from others
- Autonomous use of virtual addresses
- Recall: Virtual address 0 used differently in every process
- Underlying data protected from accidental and malicious modifications by other processes
- OS allocates frames exclusively to processes (leading to disjoint portions of RAM for different processes)
- Unless frames are explicitly shared between processes
- Autonomous use of virtual addresses
- Processes may partition address space
- Read-only region holding machine instructions, called text
- Writable region(s) holding rest (data, stack, heap)
Copy-On-Write Drawing
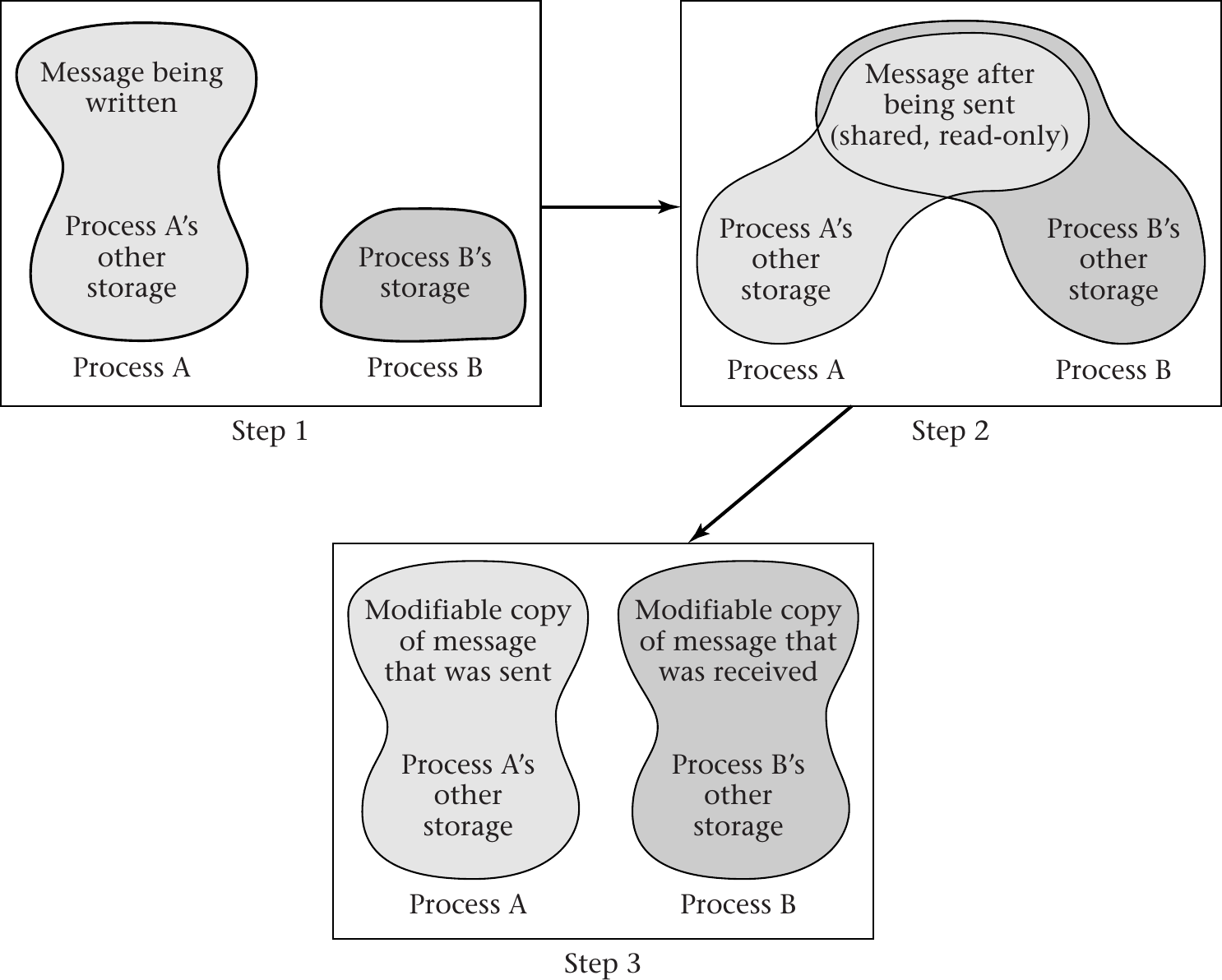
“Figure 6.4 of [Hai17]” by Max Hailperin under CC BY-SA 3.0; converted from GitHub
GNU/Linux Reporting: smem
- User space tool to read
smapsfiles:smem - Terminology
- Virtual set size (VSS): Size of virtual address space
- Resident set size (RSS): Allocated main memory
- Standard notion, yet overestimates memory usage as lots of
memory is shared between processes
- Shared memory is added to the RSS of every sharing process
- Standard notion, yet overestimates memory usage as lots of
memory is shared between processes
- Unique set size (USS): memory allocated exclusively to process
- That much would be returned upon process’ termination
- Proportional set size (PSS): USS plus “fair share” of shared pages
- If page shared by 5 processes, each gets a fifth of a page added to its PSS
Flexible Memory Allocation
- Allocation of RAM does not need to be contiguous
- Large portions of RAM can be allocated via individual frames
- Which may or may not be contiguous
- The virtual address space can be contiguous, though
- Large portions of RAM can be allocated via individual frames
Non-Contiguous Allocation

“Figure 6.9 of [Hai17]” by Max Hailperin under CC BY-SA 3.0; converted from GitHub
Persistence
- Data kept persistently in files on secondary storage
When process opens file, file can be mapped into virtual address space
- Initially without loading data into RAM
- Page accesses in that file trigger page faults
- Handled by OS by loading those pages into RAM
- Marked read-only and clean
- Handled by OS by loading those pages into RAM
- Upon write, MMU triggers interrupt, OS makes page writable and
remembers it as dirty (changed from clean)
- Typically with MMU hardware support via dirty bit in page table
- Dirty = to be written to secondary storage at some point in time
- After being written, marked as clean and read-only
Paging
Pages and Page Tables
- Mapping between virtual and physical addresses does not happen at
level of bytes
- Instead, larger blocks of memory, say 4 KiB
- Blocks of virtual memory are called pages
- Blocks of physical memory (RAM) are called (page) frames
- Instead, larger blocks of memory, say 4 KiB
- Virtual address spaces split into pages, RAM into frames
- Page is unit of transfer by OS
- OS manages a page table per process
- One entry per page
- In what frame is page located (if present in RAM)
- Additional information: Is page read-only, executable, or modified (from an on-disk version)?
- One entry per page
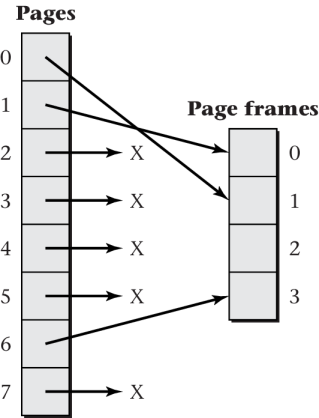
Sample Memory Allocation
Sample allocation of frames to some process
![Figure 6.10 of cite:Hai17]()
“Figure 6.10 of [Hai17]” by Max Hailperin under CC BY-SA 3.0; converted from GitHub
Page Tables
- Page Table = Data structure managed by OS
- Per process
- Table contains one entry per page of virtual address space
- Each entry contains
- Frame number for page in RAM (if present in RAM)
- Control bits (not standardized, e.g., valid, read-only, dirty, executable)
- Note: Page tables do not contain page numbers as they are implicitly given by row numbers (starting from 0)
- Note on following sample page table
- “0” as valid bit indicates that page is not present in RAM, so value under “Frame#” does not matter and is shown as “X”
- Each entry contains
Sample Page Table
Consider previously shown RAM allocation (Fig. 6.10)
![Figure 6.10 of cite:Hai17]()
“Figure 6.10 of [Hai17]” by Max Hailperin under CC BY-SA 3.0; converted from GitHub
Page table for that situation (Fig. 6.11)
Valid Frame# 1 1 1 0 0 X 0 X 0 X 0 X 1 3 0 X
Address Translation Example
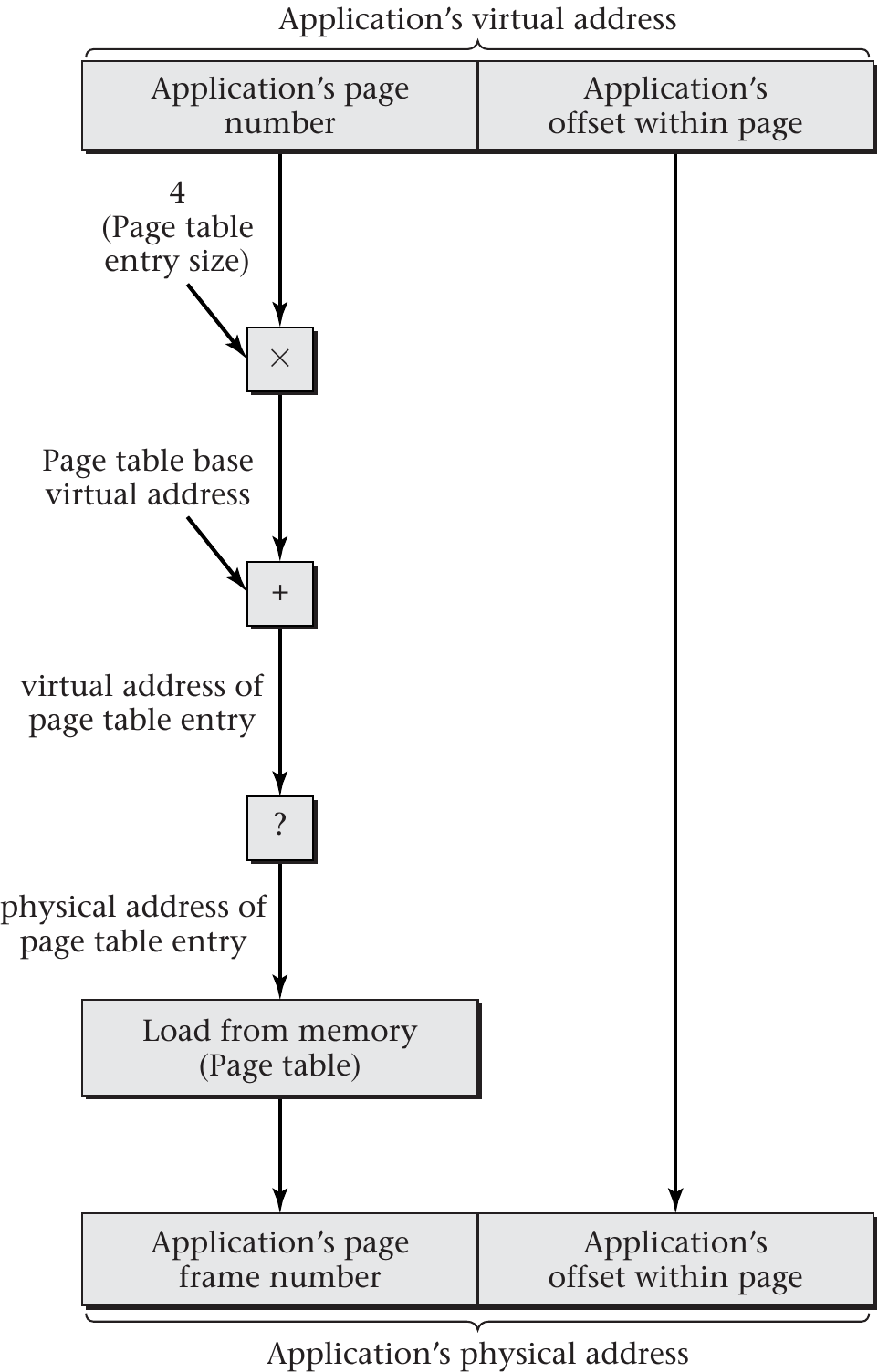
“Figure 6.4 of [Hai17]” by Max Hailperin under CC BY-SA 3.0; converted from GitHub
Is complex memory management scheme necessary?
- It depends!
TinyOS ([TinyOS])
The language(NeS) does NOT support dynamic memory allocation; components statically declare all of a program’s state, which prevents memory fragmentation as well as runtime allocation failures. The restriction sounds more onerous than it is in practice; the component abstraction eliminates many of the needs for dynamic allocation. In the few rare instances that it is truly needed (e.g., TinyDB ), a memory pool component can be shared by a set of cooperating components.
Multitasking
Multitasking
- Fundamental OS service: Multitasking
- Manage multiple computations going on at the same time
- E.g., reading multiples sensor and transceiving data via Wifi/Ethernet
- OS supports multitasking via scheduling
- Decide what computation to execute when on what CPU core
- Recall: Frequently per second, time-sliced, beyond human perception
- Decide what computation to execute when on what CPU core
- Multitasking introduces concurrency
- (Details and challenges in the next section)
- Recall: Even with single CPU core, illusion of “simultaneous” or “parallel” computations
- (Later presentation: Advantages include improved responsiveness and improved resource usage)
Thread
Process vs Thread
- Various technical terms for “computations”: Jobs, tasks, processes, threads, …
- We use only thread and process
- Process
- Container for related threads and their resources
- Created upon start of program and by programs (child processes)
- Unit of management and protection (threads from different processes are isolated from another)
- Thread
- Unit of scheduling and concurrency
- Sequence of instructions (to be executed on CPU core)
- Single process may contain just one or several threads, e.g.:
- Endpoints reading multiple sensors and transceiving data via network interfaces
- Web server handling requests from different clients in different threads sharing same code
Threads!

Threads!
© 2016 Julia Evans, all rights reserved; from julia's drawings. Displayed here with personal permission.
Thread Terminology
- Parallelism
- Concurrency
- Thread preemption
- I/O bound vs CPU bound threads
Parallelism
- Parallelism = simultaneous execution
- E.g., multi-core
- Potential speedup for computations!
- (Limited by Amdahl’s law)
- Note
- Processors contain more and more cores
- Individual cores do not become much faster any longer
- Moore’s law is slowing down
- Consequence: Need parallel programming to take advantage of current hardware
Concurrency
Concurrency is more general term than parallelism
- Concurrency includes
Parallel threads (on multiple CPU cores)
- (Executing different code in general)
Interleaved threads (taking turns on single CPU core)
- With gaps on single core!
- Challenges and solutions for concurrency apply to parallel and interleaved executions
- Concurrency includes


Thread Preemption
- Preemption = temporary removal of thread from CPU by OS
- Before thread is finished (with later continuation)
- To allow others to continue after scheduling decision by OS
- Typical technique in modern OSs
- Run lots of threads for brief intervals per second; creates illusion of parallel executions, even on single-core CPU
- Before thread is finished (with later continuation)
Thread Classification
- I/O bound
- Threads spending most time submitting and waiting for I/O requests
- Run frequently by OS, but only for short periods of time
- Until next I/O operation
- E.g., reading sensors, transmitting data
- CPU bound
- Threads spending most time executing code
- Run for longer periods of time
- Until preempted by scheduler
- E.g., video compression
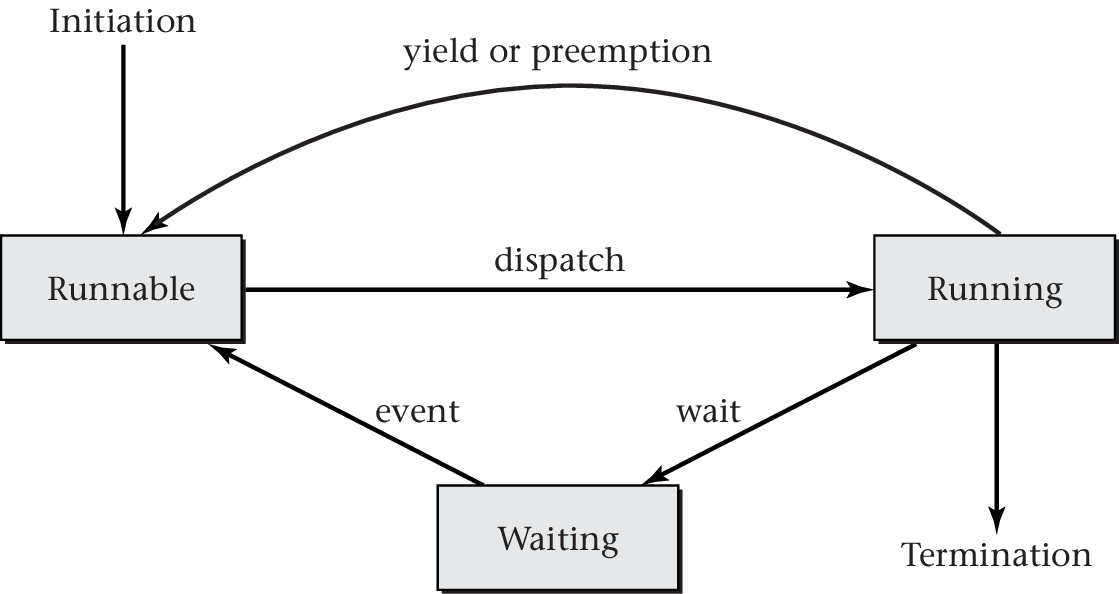
OS Thread States
- Different OSs distinguish different sets of states; typically:
- Running: Thread(s) currently executing on CPU (cores)
- Runnable: Threads ready to perform computations
- Waiting or blocked: Threads waiting for some event to occur
- OS manages states via queues
(with suitable data structures)
- Run queue(s): Potentially per CPU core
- Containing runnable threads, input for scheduler
- Wait queue(s): Potentially per event (type)
- Containing waiting threads
- OS inserts running thread here upon blocking system call
- OS moves thread from here to run queue when event occurs
- Containing waiting threads
- Run queue(s): Potentially per CPU core
Thread State Transitions
Main Reasons for Threads
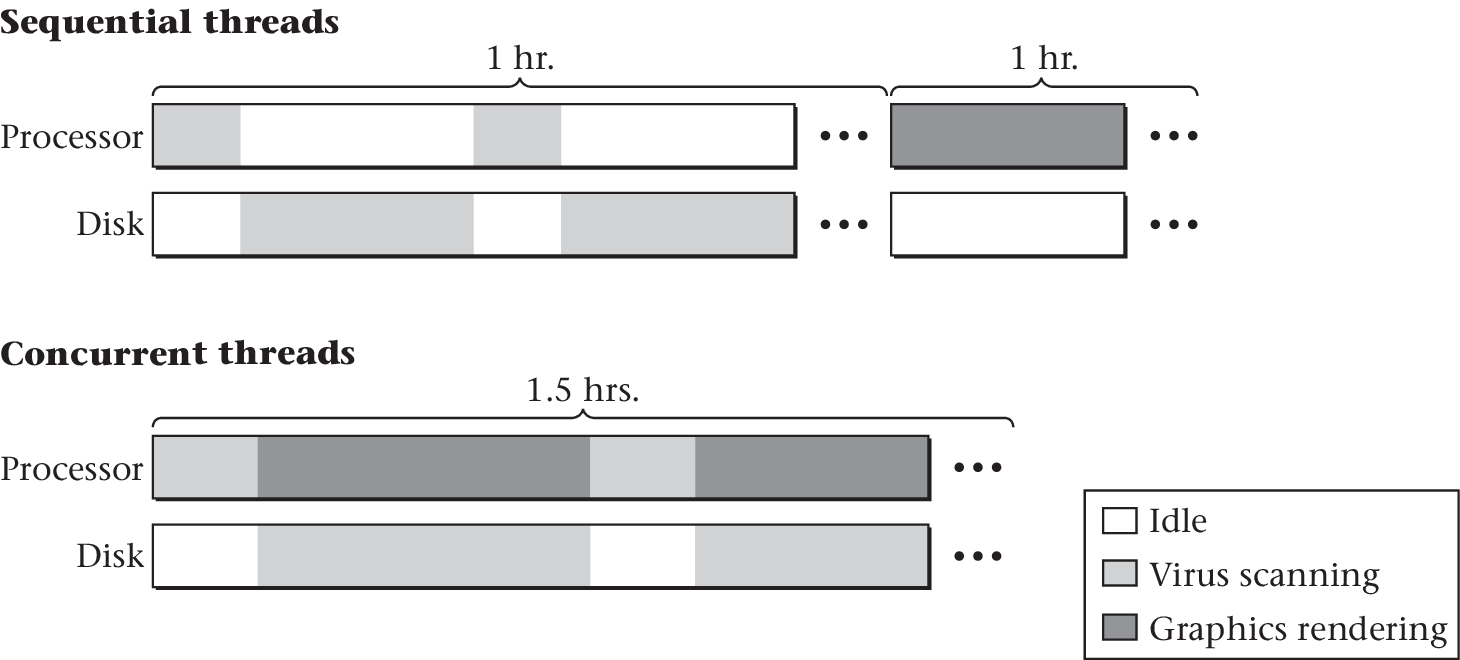
- Resource utilization
- Keep most of the hardware resources busy most of the time, e.g.:
- While one thread is waiting for external event (e.g., waiting for sensor reading/transmission to finish), allow other threads to continue
- Keep multiple cores busy
- E.g., OS housekeeping such as zeroing of memory on second core
- Keep most of the hardware resources busy most of the time, e.g.:
- Responsiveness
- Use separate threads to react quickly to external events
- More modular design
Interleaved Execution Example
Thread Switching
- With multiple threads, OS needs to decide which to execute when
→ Scheduling
- (Similar to machine scheduling for industrial production, which you may know from operations management)
- Recall multitasking
- OS may use time-slicing to schedule threads for short intervals, illusion of parallelism on single CPU core
- After that decision, a context switch (thread switch) takes place
- Remove thread A from CPU
- Remember A’s state (instruction pointer/program counter, register contents, stack, …)
- Dispatch thread B to CPU
- Restore B’s state
- Remove thread A from CPU
Thread Switching with yield
In the following
- First, simplified setting of voluntary switch from thread A to
thread B
- Function
switchFromTo()on next slide- For details, see Sec. 2.4 in [Hai19]
- Leaving the CPU voluntarily is called yielding;
yield()may really be an OS system call
- Function
- Afterwards, the real thing: Preemption by the OS
Interleaved Instruction Sequence
![Interleaved execution of threads. Based on [[https://github.com/Max-Hailperin/Operating-Systems-and-Middleware--Supporting-Controlled-Interaction/][Figure 2.7 of book by Max Hailperin]], CC BY-SA 3.0.](figures/raw/3-interleaved-executions.png)
Interleaved execution of threads. Based on Figure 2.7 of book by Max Hailperin, CC BY-SA 3.0.
by Jens Lechtenbörger under CC BY-SA 4.0; from GitLab
Cooperative Multitasking
- Approach based on
switchFromTo()is cooperative- Thread A decides to yield CPU (voluntarily)
- A hands over to B
- Thread A decides to yield CPU (voluntarily)
- Disadvantages
- Inflexible: A and B are hard-coded
- No parallelism, just interleaved execution
- What if A contains a bug and enters an infinite loop?
- Advantages
- Programmed, so full control over when and where of switches
- Programmed, so usable even in restricted environments/OSs without support for multitasking/preemption
Preemptive Multitasking
- Preemption: OS removes thread forcefully (but only
temporarily) from CPU
- Housekeeping on stacks to allow seamless continuation later on similar to cooperative approach
- OS schedules different thread for execution afterwards
- Additional mechanism: Timer interrupts
- OS defines time slice (quantum), e.g., 30ms
- Interrupt fires every 30ms
- Interrupt handler invokes OS scheduler to determine next thread
Multitasking Overhead
- OS performs scheduling, which takes time
- Thread switching creates overhead
- Minor sources: Scheduling costs, saving and restoring state
- Major sources: Cache pollution, cache coherence protocols
- After a context switch, the CPU’s cache quite likely misses
necessary data
- Necessary data needs to be fetched from RAM
- Accessing data in RAM takes hundreds of clock cycles
- After a context switch, the CPU’s cache quite likely misses
necessary data
Scheduling
- With multitasking, lots of threads share resources
- Focus here: CPU
- Scheduling (planning) and dispatching (allocation) of CPU via OS
- Non-preemptive, e.g., FIFO scheduling
- Thread on CPU until yield, termination, or blocking
- Scheduler for TinyOS
- Preemptive, e.g., Round Robin scheduling
- Examples: RTOS
- Among all threads, schedule and dispatch one, say T0
- Allow T0 to execute on CPU for some time, then preempt it
- Repeat step (1)
- Examples: RTOS
- Non-preemptive, e.g., FIFO scheduling
- (Similar decisions take place in industrial production, which you may know from operations management)
Scheduling Goals
- Performance
- Throughput
- Number of completed threads (computations, jobs) per time unit
- More important for service providers than users
- Response time
- Time from thread start or interaction to useful reaction
- Throughput
- User control
- Resource allocation
- Mechanisms for urgency or importance, e.g., priorities
Other
- Fairness (e.g., equal CPU shares per thread)
- Energy Consumption for energy constrained devices
Note: Above goals have trade-offs (discussed subsequently)
Throughput
- To increase throughput, avoid idle times of CPU
- Thus, reassign CPU when currently running thread needs to wait
- Context switching necessary
- Recall: Context switching comes with overhead
- Overhead reduces throughput
Response Time
- Frequent context switches may help for small response time
- However, their overhead hurts throughput
- Responding quickly to one thread may slow down another one
- May use priorities to indicate preferences
Scheduling Mechanisms
Three Families of Schedulers
- Fixed thread priorities
- Dynamically adjusted thread priorities
- Controlling proportional shares of processing time
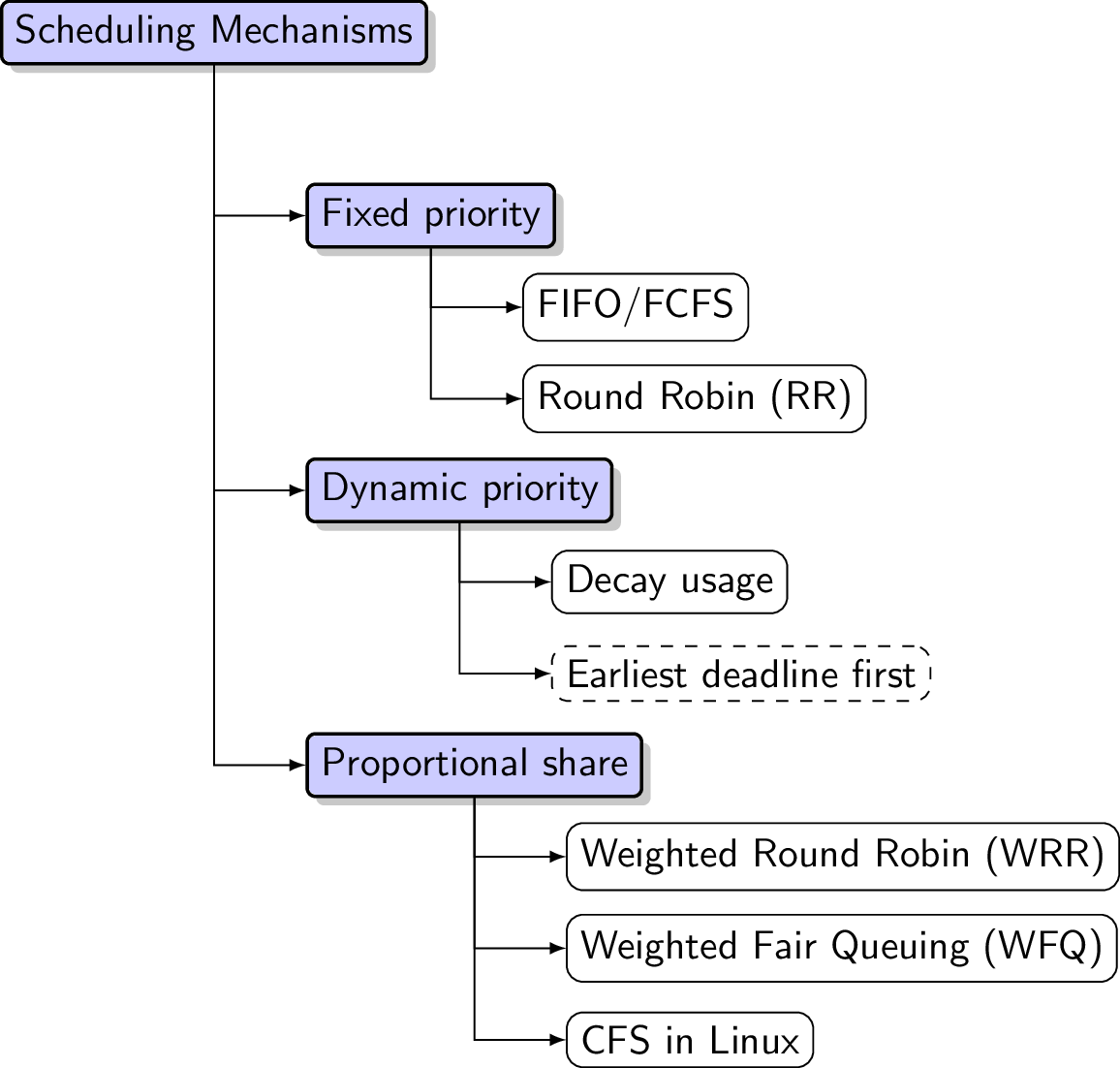
Fixed-Priority Scheduling
- Use fixed, numerical priority per thread
- Threads with higher priority preferred over others
- Smaller or higher numbers may indicate higher priority: OS dependent
- Threads with higher priority preferred over others
- Implementation alternatives
- Single queue ordered by priority
- Or one queue per priority
- OS schedules threads from highest-priority non-empty queue
- Scheduling whenever CPU idle or some thread becomes runnable
- Dispatch thread of highest priority
- In case of ties: Run one until end (FIFO) or serve all Round Robin
- Dispatch thread of highest priority
Warning on Fixed-Priority Scheduling
- Starvation of low-priority threads possible
- Starvation = continued denial of resource
- Here, low-priority threads do not receive resource CPU as long as threads with higher priority exist
- Careful design necessary
- E.g., for hard-real-time systems (such as cars, aircrafts, power plants)
- Starvation = continued denial of resource
FIFO/FCFS Scheduling
- FIFO = First in, first out
- (= FCFS = first come, first served)
- Think of queue in supermarket
- Non-preemptive strategy: Run first thread until completed (or blocked)
- For threads of equal priority
Round Robin Scheduling
Key ingredients
- Time slice (quantum, q)
- Timer with interrupt, e.g., every 30ms
- Queue(s) for runnable threads
- Newly created thread inserted at end
- Scheduling when (1) timer interrupt triggered or (2) thread ends
or is blocked
- Timer interrupt: Preempt running thread
- Move previously running thread to end of runnable queue (for its priority)
- Dispatch thread at head of queue (for highest priority) to CPU
- With new timer for full time slice
- Thread ends or is blocked
- Cancel its timer, dispatch thread at head of queue (for full time slice)
- Timer interrupt: Preempt running thread
- Time slice (quantum, q)
Dynamic-Priority Scheduling
- With dynamic strategies, OS can adjust thread priorities during execution
- Sample strategies
- Earliest deadline first
- For tasks with deadlines — discussed in [Hai19]
- Decay Usage Scheduling
- Earliest deadline first
WRR vs WFQ with sample Gantt Charts
- Threads T1, T2, T3 with weights 3, 2, 1; q = 10ms
- Supposed order of arrival: T1 first, T2 second, T3 third
- If threads are not done after shown sequence, start over with T1


CFS in Linux
- CFS = Completely fair scheduler
- Actually, variant of WRR above
- Weights determined via so-called niceness values
- (Lower niceness means higher priority)
- Weights determined via so-called niceness values
- Actually, variant of WRR above
- Core idea
- Keep track of how much threads were on CPU
- Scaled according to weight
- Called virtual runtime
- Represented efficiently via red-black tree
- Schedule thread that is furthest behind
- Until preempted or time slice runs out
- (Some details in [Hai19])
- Keep track of how much threads were on CPU
Synchronizations
Race Conditions
Central Challenge for Concurrency: Races

“Ferrari Kiss” by Antoine Valentini under CC BY-SA 2.0; from flickr
Races (1/2)
- Race (condition): a technical term
- Multiple activities access shared resources
- At least one writes, in parallel or concurrently
- Overall outcome depends on subtle timing differences
- “Nondeterminism” (recall Dijkstra on interrupts)
- Missing synchronization
- Bug!
- Multiple activities access shared resources
- Previous picture
- Cars are activities
- Street segments represent shared resources
- Timing determines whether a crash occurs or not
- Crash = misjudgment = missing synchronization
Races (2/2)
- OS
- Threads are activities
- Variables, memory, files are shared resources
- Missing synchronization is a bug, leading to anomalies just as in database systems
What happened in our Python program?
| Time | Thread 1 | Thread 2 | Variables |
| 1 | c = x | \(x = 0, t1.c = 0, t2.c = 0\) | |
| 2 | c += 1 | \(x = 0, t1.c = 1, t2.c = 0\) | |
| 3 | c = x | \(x = 0, t1.c = 1, t2.c = 0\) | |
| 4 | x = c | \(x = 1, t1.c = 1, t2.c = 0\) | |
| 5 | c += 1 | \(x = 1, t1.c = 1, t2.c = 1\) | |
| 6 | x = c | \(x = 1, t1.c = 1, t2.c = 1\) |
What if we use the following increment_global function:
def increment_global(): global x x += 1
Atomicity
An atomic action is one that appears to take place as a single indivisible operation:
- a process switch can’t happen during an atomic action, so
- no other action can be interleaved with an atomic action; and
- no other process can interfere with the manipulation of data by an atomic action
- some, but not all, machine instructions are atomic
- E.g., increasing a register
Non-Atomic Executions
- Races generally result from non-atomic executions
- Even “single” instructions such as
x += 1are not atomic- Execution via sequences of machine instructions
- Load variable’s value from RAM
- Perform add in ALU
- Write result to RAM
- Execution via sequences of machine instructions
- A context switch may happen after any of these machine instructions, i.e., “in the middle” of a high-level instruction
- Intermediate results accessible elsewhere
- Even “single” instructions such as
Dijkstra on Interrupts
- “It was a great invention, but also a Box of Pandora. Because the exact moments of the interrupts were unpredictable and outside our control, the interrupt mechanism turned the computer into a nondeterministic machine with a nonreproducible behavior, and could we control such a beast?”
- “When Loopstra and Scholten suggested this feature for the X1, our next machine, I got visions of my program causing irreproducible errors and I panicked.”
Locking
Goal and Solutions (1/2)
- Goal
- Concurrent executions that access shared resources should be isolated from one another
- Conceptual solution
- Declare critical sections (CSs)
- CS = Block of code with potential for
race conditions on shared resources
- Cf. transaction as sequence of operations on shared data
- CS = Block of code with potential for
race conditions on shared resources
- Enforce mutual exclusion (MX) on CSs
- At most one thread inside CS at any point in time
- This avoids race conditions
- Cf. serializability for transactions
- At most one thread inside CS at any point in time
- Declare critical sections (CSs)
Goal and Solutions (2/2)
- New goal
- Implementations/mechanisms for MX on CS
- Solutions
- Locks, also called mutexes
- Acquire lock/mutex at start of CS, release it at end
- Choices: Busy waiting (spinning) or blocking when lock/mutex not free?
- Acquire lock/mutex at start of CS, release it at end
- Semaphores
- Abstract datatype, generalization of locks, blocking, signaling
- Monitors
- Locks, also called mutexes
Locks and Mutexes
- Lock (mutex) = object with methods
lock()oracquire(): Lock/acquire/take the object- A lock can only be
lock()’ed by one thread at a time - Further threads trying to
lock()need to wait forunlock()
- A lock can only be
unlock()orrelease(): Unlock/release the object- Can be
lock()’ed again afterwards
- Can be
- E.g., interface threading.lock in Python.

“Figure 4.4 of [Hai17]” by Max Hailperin under CC BY-SA 3.0; converted from GitHub
Challenges
- Above solutions restrict entry to CS
- Thus, they restrict access to the resource CPU
- Major synchronization challenges arise
- Starvation
- Thread never enters CS
- More generally: never receives some resource, e.g.,
- Thread never enters CS
- Deadlock
- Set of threads is stuck
- Circular wait for additional locks/semaphores/resources/…
- In addition, programming errors
- Difficult to locate, time-dependent
- Difficult to reproduce, “non-determinism”
- Starvation
Starvation
- A thread starves if its resource requests are repeatedly denied
- Examples in previous presentations
- Thread with low priority in presence of high priority threads
- Thread which cannot enter CS
- Famous illustration: Dining philosophers (next slide)
- No simple solutions
Dining Philosophers
- MX problem proposed by Dijkstra
- Philosophers sit in circle; eat and think repeatedly
- Two forks required for eating
- MX for forks
- Two forks required for eating
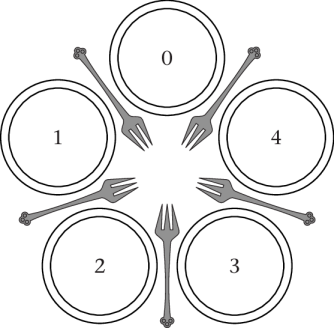
Dining Philosophers
“Figure 4.20 of [Hai17]” by Max Hailperin under CC BY-SA 3.0; converted from GitHub
Priority Inversion
- In general, if threads with different priorities exist, the OS should run those with high priority in preference to those with lower priority.
- “priority inversion” denotes phenomena, where low-priority threads hinder the progress of high-priority threads.
- intuitively this should not happen.
Example
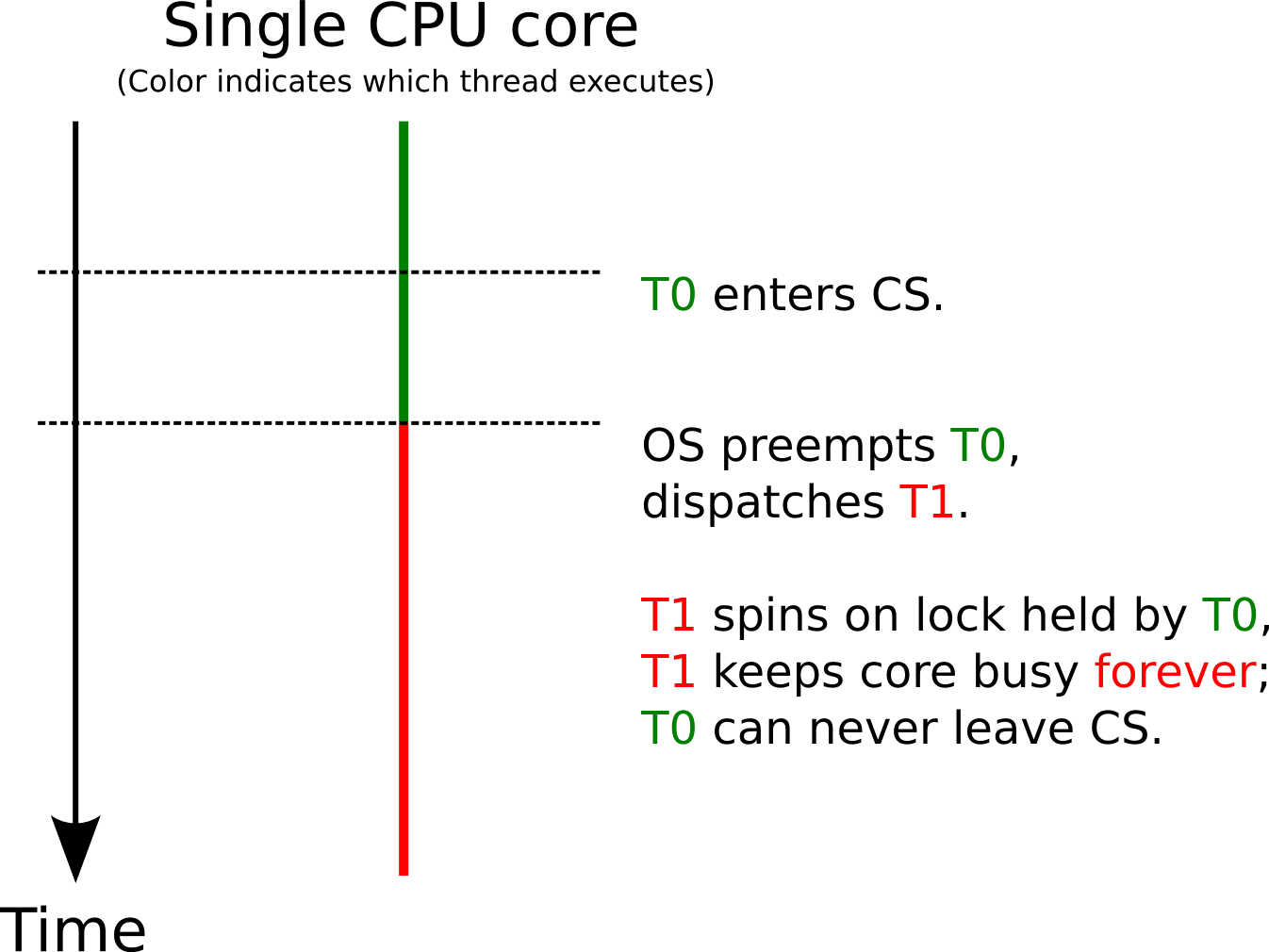
- Example; single CPU core (visualization on next slide)
- Thread T0 with low priority enters CS
- T0 preempted by OS for T1 with high priority
- E.g., an important event occurs, to be handled by T1
- Note that T0 is still inside CS, holds lock
- T1 tries to enter same CS and spins on lock held by T0
- This is a variant of priority inversion
- High-priority thread T1 cannot continue due to actions by low-priority thread
- If just one CPU core exists: Low-priority thread T0
cannot continue
- As CPU occupied by T1
- Deadlock
- If multiple cores exist: Low-priority thread T0 runs although thread with higher priority does not make progress
- If just one CPU core exists: Low-priority thread T0
cannot continue
- High-priority thread T1 cannot continue due to actions by low-priority thread
Single Core
Embedded OS
TinyOS
- System configuration consists of
- a Tiny scheduler; and
- a Graph of components
- Event-driven architecture
- Single shared stack
- NO process/memory management, virtual memory
- Written in NesC (Network Embedded Systems C), which is an extension of C
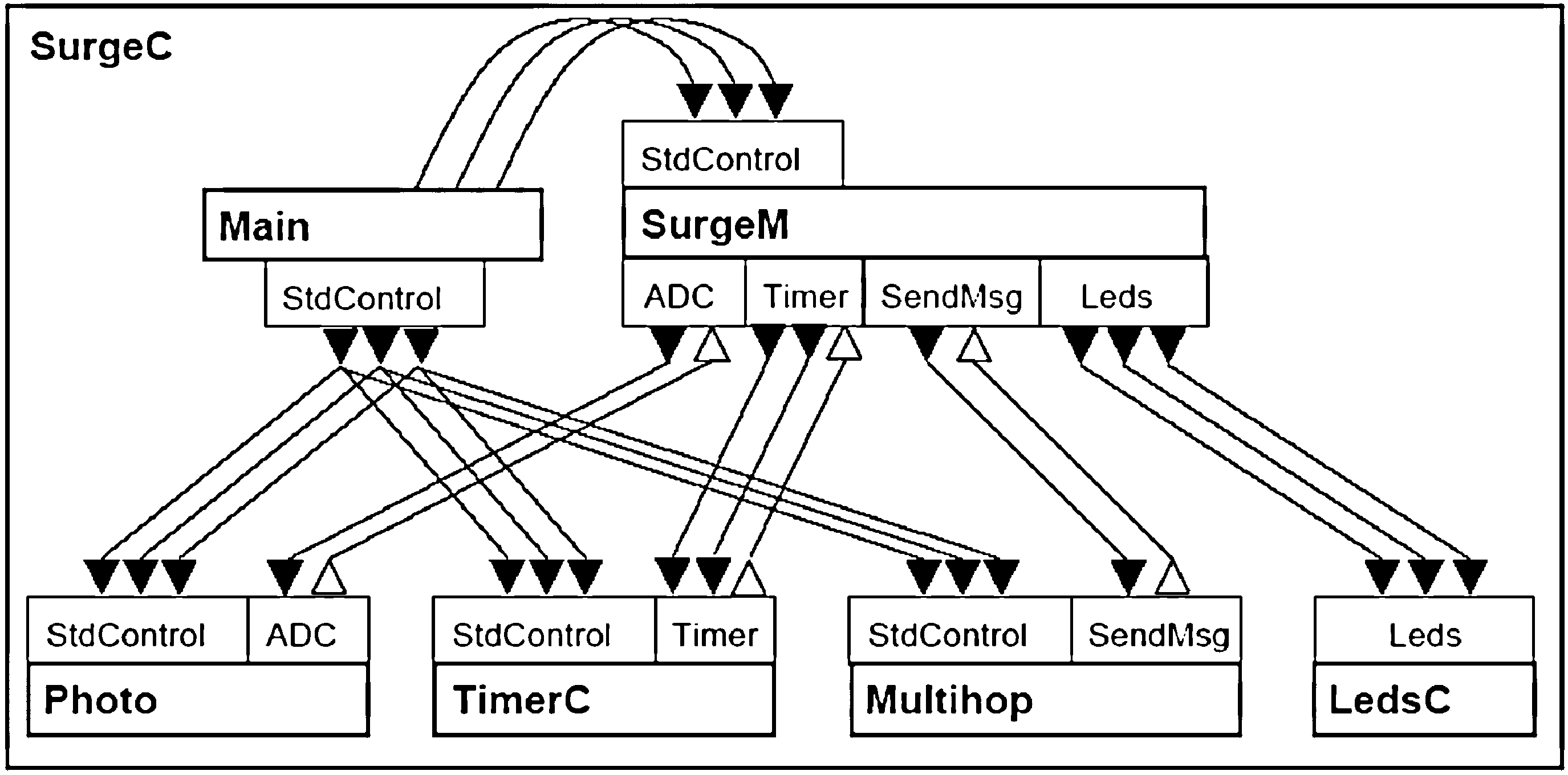
TinyOS: Application
- Application SurgeC:
- periodically (TimerC) acquires light sensor readings (Photo), and
- sends them back to a base station using multi-hop routing (Multihop)
![Figure]()
SurgeC
TinyOS: Component
- A Component has:
- Frame (internal state)
- One per component
- Statically allocated
- Allows to know the memory requirements of a component at compile time
- Prevents memory/execution time overhead with dynamic allocation
- Tasks (computation)
- Interface (events, commands)
- Frame (internal state)
- Commands and Events are function calls
- Application: linking/glueing interfaces (events, commands)
TinyOS: Command
- Commands:
- E.g., Leds.led1Toggle, Timer.startPeriodic, Sensor.Read
- are non-blocking
- postpone time consuming work by posting a task
- can be called by event, tasks, or higher-level command
- can call lower-level commands, post tasks
TinyOS: Event
- Events:
- E.g., Timer.fired, Read.readDone, Boot.booted
- Events are signaled by hardware interrupt, or lower-level event
- Commands cannot signal events
- An event handler can post tasks, signal higher-level events or call lower-level commands.
- A hardware event triggers a fountain of processing that goes upward through events and can bend downward through commands
TinyOS: Tasks
- Tasks:
- FIFO scheduling when not preempted by other events
- Perform low priority/time consuming work
- Can be posted by other events or commands
- Run to completion
TinyOS: Example
module BlinkTaskC { uses interface Timer<TMilli> as Timer0; uses interface Leds; uses interface Boot; } implementation { task void toggle() { call Leds.led0Toggle(); } event void Boot.booted() { call Timer0.startPeriodic( 1000 ); } event void Timer0.fired() { post toggle(); } }
TinyOS: Reactive Concurrency
- Two-level scheduling: events and tasks
- Scheduler is simple FIFO
- a task cannot preempt another task
- events preempt tasks (higher priority)
- event may preempt another event
- Use task to make event/command smaller
![Figure]()
Two-Level Scheduling
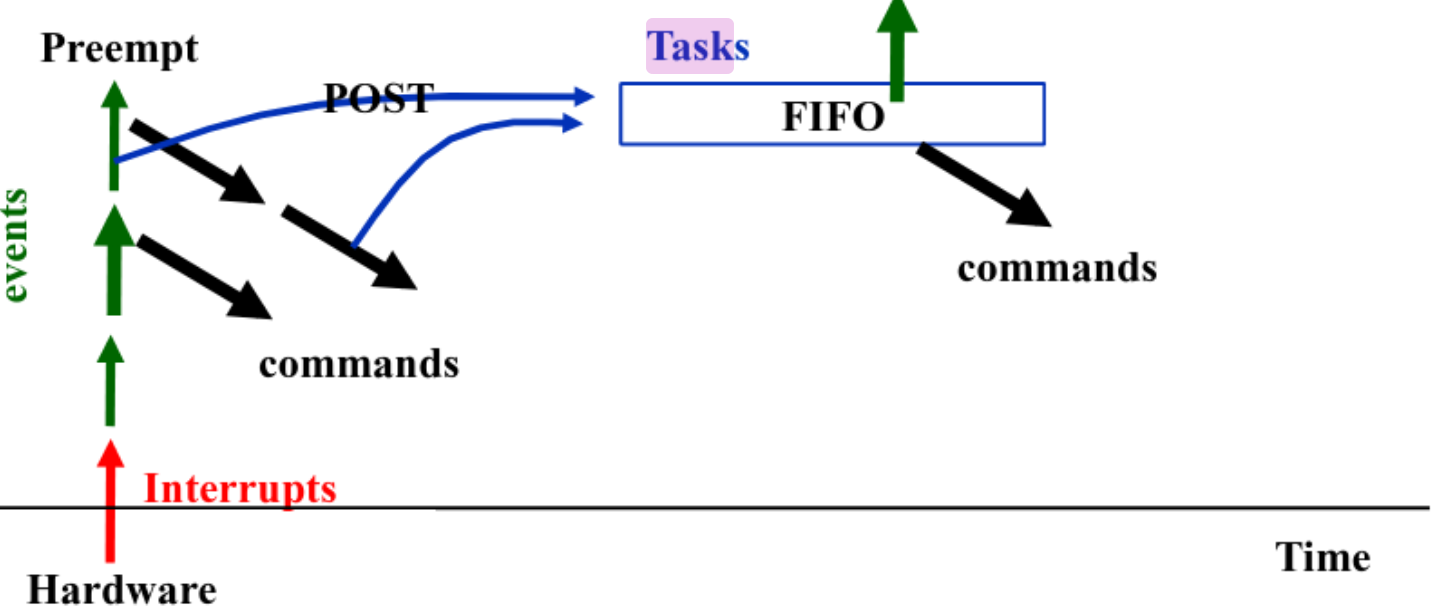
TinyOS: Synchronization
- Race-Free Invariant: Any update to shared state is
- either done only by tasks (CANNOT be preempted by other tasks), or
- occurs in an atomic section (by disabling CPU interrupt).
- Invariance is enforced during compilation.
Advantages of TinyOS
- Small Overhead: E.g., 15kB for SurgeC
- Low Power Consumption
- Reactive Concurrency:
- Race detection at compilation
- Minimal context switch(FIFO for tasks)
- Real-time response (for event)
- Flexible from component based design
FreeRTOS
- Small and Portable
- Kernel contains only 3 files: tasks.c, list.c, queue.c
- Well supported
- has been ported to over 35 micro-controller platforms
- integration with Amazon Web Service
- Modular
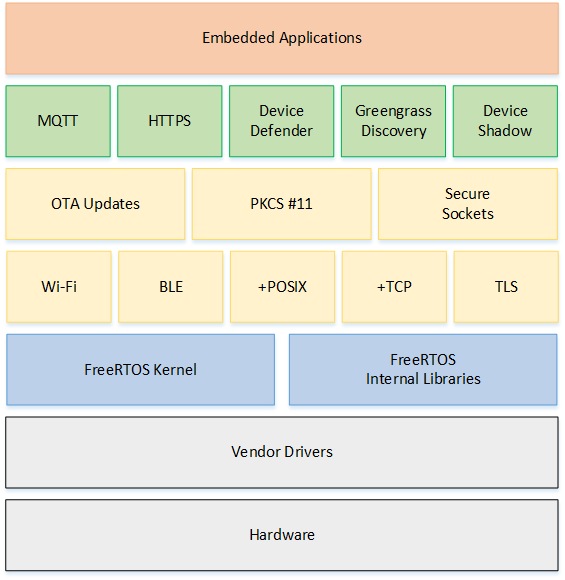
FreeRTOS Architecture
FreeRTOS: Memory Management
Support:
- Fully static allocation.
- Dynamic Allocation
- allocate only;
- allocate and free with a very simple, fast, algorithm;
- a more complex but fast allocate and free algorithm with memory coalescence;
- an alternative to the more complex scheme that includes memory coalescence that allows a heap to be broken across multiple memory areas.
- and C library allocate and free with some mutual exclusion protection.
FreeRTOS: Multitasking
- Round-robin scheduling with priority
- Time slice duration set by the user (usually 1ms to 10ms)
- Real-time guarantees
- Support mutex and semaphores
![Figure]()
FreeRTOS Scheduler
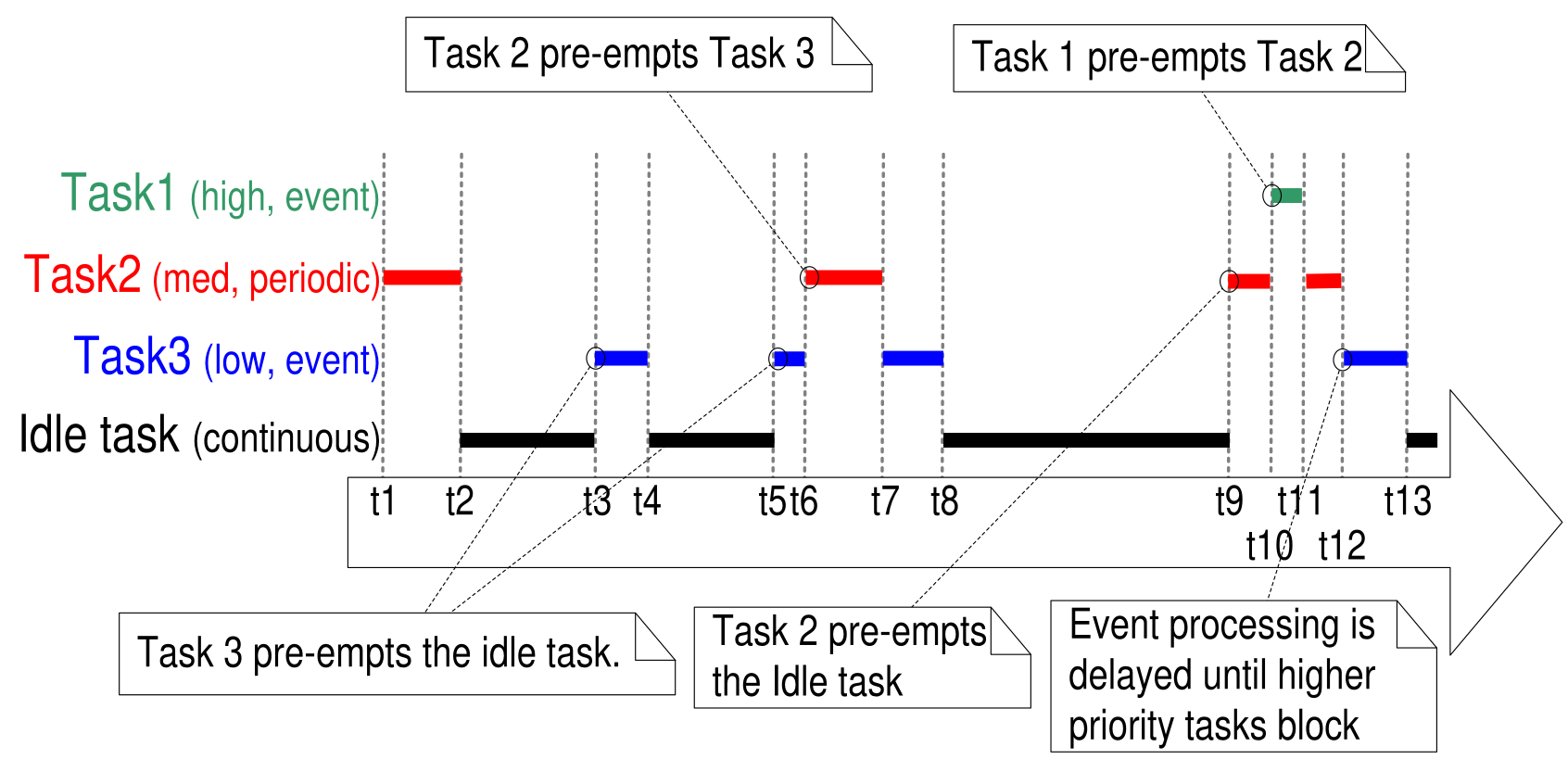
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comparison
| Bare Metal | TinyOS | FreeRTOS | Linux | |
| Overhead | None | Small | Small | Large |
| Scheduler | Single Thread | FIFO + Interrupt | Round-Robin, Real-time | CFS, NOT real-time |
| Synchronization | None | Resolved at Compilation | Mutex, Semaphores | Multiple Locking Types |
| Memory | Static | Static | Static or 5 Dynamic schemes | Full fledged Memory Management |
Conclusions
Summary: OS
- OS is Software
- that uses hardware resources of a computer system
- to provide support for the execution of other software.
- OS kernel
- provides interface for applications and
- manages resources.
Summary: Memory Management
- Virtual memory provides abstraction over RAM and secondary storage
- Isolation of processes
- Sharing of common code or data
- Flexible memory management
- Page tables managed by OS
- Each process has its own page table
Summary: Multitasking
- Threads represent individual instruction execution sequences
- Multithreading improves
- Resource utilization
- Responsiveness
- Modular design in presence of concurrency
- OS performs scheduling for shared resources
- CPU scheduling
- Subject to conflicting goals
- CPU scheduling based on thread states and priorities
- Fixed vs dynamic priorities vs proportional share
Summary: Synchronization
- Parallelism is a fact of life
- Multi-core, multi-threaded programming
- Race conditions arise
- Synchronization is necessary
- Mutual exclusion for critical section
- Locking
- Monitors
- Semaphores
Bibliography
- [Hai19] Hailperin, Operating Systems and Middleware – Supporting Controlled Interaction, revised edition 1.3.1, 2019. https://gustavus.edu/mcs/max/os-book/
- [Sta01] Stallings, Operating Systems: Internals and Design Principles, Prentice Hall, 2001.
- [Tan01] Tanenbaum, Modern Operating Systems, Prentice-Hall, 2001.
- [TinyOS] Levis, Madden, Polastre, Szewczyk, Whitehouse, Woo, Gay, Hill, Welsh, Brewer & Culler, TinyOS: An Operating System for Sensor Networks, Springer Berlin Heidelberg, 2005. https://doi.org/10.1007/3-540-27139-2\_7